
Nftables es un proyecto de netfilter que proporciona filtrado de paquetes y clasificación de paquetes en Linux. Es la evolución de iptables, y, de hecho, las reemplaza (no se puede mezclar nftables y iptables). Nftables es capaz de reemplazar en el mismo framework a iptables, ip6tables, arptables y ebtables, y todo ello bajo el mismo espacio de usuario (nft) y compatibilidad hacia atrás (con sintaxis iptables). Nftables es el framework por defecto en Debian 10, aunque no está activado por defecto ya que se sigue usando sintaxis iptables, pero por poco tiempo.
Si vas a probar Nftables en Linux, en RedesZone te explicamos cada uno de los puntos que debes tener en cuenta a la hora de instalar este framwork que sustiye a iptables. Para ello, hablaremos de las principales características que presenta, además de cómo funciona. De esta manera podrás conocer más a fondo este proyecto que está desarrollado para analizar y clasificar los paquetes de red. Por lo que conseguirás configurarlo desde cero en tu equipo Linux.
Qué es nftables
Nftables se trata de un proyecto dedicado al filtrado de paquetes y su clasificación en Linux. Este es el sustituto de los frameworks como iptables, ip6tables, arptables o ebtables. Los componentes en núcleo de Linux y su línea de comandos en el apartado del usuario, se combinan en las nftables.
Esto proporciona muchas facilidades en el filtrado de paquetes. Con numerosas mejoras en rendimiento, características y facilidad de uso. En comparación con otras herramientas de filtrado existentes. Algunas de las características principales son:
- Tablas de búsqueda sustituyendo al procesamiento lineal.
- Tiene un único marco para los protocolos IPv4 e IPv6.
- Aplica reglas en lugar de buscar, actualizar y almacenar un conjunto completo de estas.
- Soporta la depuración y rastreo en los conjuntos de reglas y la supervisión de los eventos de rastreo.
- Tiene una sintaxis más coherente y compacta. Lo cual hace que sea más sencillo de utilizar.
- No contiene extensiones específicas de protocolo.
- Cuenta con una API Netlink, para que otras aplicaciones de terceros las puedan implementar.
Del mismo modo que con iptables, estas utilizan tablas para el almacenamiento de las cadenas. Estas cadenas, a su vez, contienen reglas individuales para poder llevar a cabo todas las acciones. La herramienta que se encarga del filtrado, sustituyendo a las anteriores, es nft. La cual cuenta con una biblioteca que se puede utilizar para interactuar a bajo nivel con la API.
Si queremos visualizar todos los módulos con sus conjuntos de reglas, podemos hacerlo con nft list rule set. Y nos encontraremos herramientas que añaden más tablas, cadenas, reglas y conjuntos. Pero debemos tener en cuenta que todo esto puede afectar a los conjuntos ya existentes que están instalados. Esto es porque se utiliza un sistema de comandos heredados. Si estás mirando la forma en la que migrar de iptables a nftables. Te podemos decir que es un proceso sencillo, ya que se pueden migrar también las reglas que tenemos creadas de uno a otro.
Introducción a nftables
Si utilizamos el sistema Debian 10 en adelante, el framework que viene instalado por defecto es nftables, aunque tenemos la posibilidad de seguir utilizando la sintaxis iptables sin problemas, pero la «base» es la nueva nftables. Para usar la sintaxis nueva, simplemente tenemos que instalarlo desde los repositorios oficiales. Nftables es compatible con Kernel Linux 3.13 en adelante, pero es recomendable usar un Kernel 4.7 en adelante, Debian 10 usa Kernel 4.19, por lo que nos funcionará perfectamente.
El framework de iptables sufre una serie de limitaciones que se han querido mejorar con este nuevo framework:
- Evitar duplicidad e inconsistencia en el código fuente.
- Muchas extensiones de iptables estaban duplicadas con pequeños cambios para interactuar con diferentes protocolos.
- Simplificar usabilidad en entornos IPv4/IPv6.
- Mejorar actualizaciones al conjunto de reglas. Esta tarea en iptables es muy costosa y poco escalable.
- Mejorar la sintaxis.
Esta herramienta nos proporciona muchas facilidades para clasificar paquetes, y se le considera el sucesor de iptables y arptables, por ejemplo. Pero este nos ofrece muchas mejoras en comparación con las anteriores en cuanto al filtrado de los paquetes. Algunas de sus características son:
- Utiliza tablas de búsqueda en lugar de un procesamiento lineal.
- Da uso de un único marco para los protocolos IPv4 e IPv6.
- Cuenta con reglas aplicadas en lugar de buscar, actualizar y almacenar un conjunto de reglas.
- Da soporte a la depuración y el rastreo para el conjunto de las redes con nftrace, y para supervisar el rastreo de eventos.
- Tiene una sintaxis más coherente y compactada, sin muchas extensiones de los protocolos.
- Cuenta con una API Netlink para aplicaciones de terceros.
En otros aspectos, también es similar a iptables, pues ambos utilizan tablas para el almacenamiento de cadenas. Estas contienen reglas individuales para llevar a cabo todas las acciones. A mayores, cuenta con la herramienta nft, la cual sustituye a todas las anteriores en cuanto al filtrado de paquetes. Otra herramienta interesante, es la biblioteca libnftnl, la cual se puede utilizar para interacciones de bajo nivel en nftables.
Si hablamos de los módulos, el conjunto de reglas de nftables, con el comando de nft, podemos ver un list rule set. Estas herramientas añaden nuevas tablas, cadenas, reglas, conjuntos y objetos a las reglas ya incorporadas. Este conjunto de operaciones junto con el comando ngt flush ruleset, lo cual puede afectar a los conjuntos de reglas que tenemos instalados a través de los comandos heredados anteriores.
También contamos con una conversión de reglas de iptables a nftables, pero debemos tener en cuenta que algunas de las extensiones no tendrán soporte en esta traducción. Para ello, utilizaremos iptables-restore-translate e ip6tables-restores-traslate para realizar la traducción del volcado de reglas.
Características y diferencias con iptables
Ahora nftables usa una sintaxis más compacta e intuitiva que fue inspirada por la herramienta tcpdump. Nftables proporciona una capa de compatibilidad con iptables, usando su misma sintaxis sobre la infraestructura de nftables (lo que se utiliza en Debian 10 si no se instala nft). En nftables, las tablas y cadenas son totalmente configurables, no hay tablas predefinidas que siempre deben estar, aunque no las usemos (como sí ocurre con iptables). Los nombres también pueden ser arbitrarios.
Otras características importantes de nftables, es que los “match” –m y los “target” –j desaparecen, nftables tiene expresiones. Nftables permite hacer varias acciones en una sola regla (varios targets), algo que con iptables no era posible fácilmente. Por defecto no tenemos contadores integrados en las reglas y cadenas, ahora son opcionales y pueden habilitarse si queremos. Por último, nftables proporciona una administración más sencilla para conjuntos de reglas IPv4 y IPv6, ahora no tendremos que «adaptar» las reglas de iptables a ip6tables como ocurría anteriormente.
Las posibilidades de realizar generalizaciones de reglas son mucho mejor, además, una característica muy importante de iptables es la funcionalidad «ipset», que nos permite permitir o bloquear millones de direcciones IP o subredes de forma eficiente. Nftables ha heredado esta misma característica, pero no es un «plugin» que tenemos que instalar, como ocurría con ipset y iptables, sino que está directamente integrado en nftables de manera nativa, y su funcionamiento es realmente fácil y sencillo.
Os recomendamos visitar la web oficial de nftables donde encontraréis todos los detalles sobre este firewall para sistemas operativos Linux.
Desventajas o inconvenientes de nftables
Dentro de esta herramienta nos encontramos con pequeños inconvenientes en comparación con otras, y hay que destacarlos, ya que a algunas personas puede resultarles importante:
- Sintaxis nueva: nftables introduce una sintaxis diferente y más moderna en comparación con iptables. Por lo que no si no estás acostumbrado, podría llevarte un tiempo tomar contacto con esta herramienta, ya que además la documentación e información que podemos encontrar sobre ella en la red es más escasa.
- Compatibilidad: no solo a nivel de hardware o software, sino a la hora de migrar estos scripts (desde iptables) puede requerir un esfuerzo considerable.
- Mensajes de error: Los mensajes de error en nftables a veces pueden ser menos descriptivos o útiles en comparación con los de iptables, lo que puede dificultar la resolución de problemas, sobre todo debido a otros aspectos como el que veremos ahora, ya que no tendremos un soporte bueno, y, por tanto, que no sepamos bien que error es, puede ser importante.
- Comunidad más pequeña: al igual que la falta de información comparada con otras herramientas, en este caso también existe una comunidad menos grande, lo que dificulta muchas soluciones y cooperación entre los usuarios, aunque cada vez está cogiendo más popularidad.
- SO de Linux: se necesita una versión del sistema operativo de 3.13 o superior, por lo que tendremos que tener un Linux actualizado, lo que puede suponer un problema para usuarios con versiones más antiguas.
No son muchos más los problemas detectados, por tanto, si cuentas con una versión de Linux reciente y no eres de las personas a las que le cuesta aprender algo nuevo, la verdad es que son pocos los inconvenientes que verás, y, por tanto, puedes ponerte a ello.
Puesta en marcha de nftables en Debian 10
Para poner en marcha nftables en Debian 10, simplemente debemos instalar el frontend, todo lo demás ya está instalado (y se usa, aunque pongamos iptables).
sudo apt install nftables
No es necesario reiniciar el ordenador o el servidor, no se toca nada del Kernel, solamente el frontend de administración del firewall, que ahora pasa de estar en iptables, a estar con la sintaxis de nftables. Un detalle muy importante es que nftables hace una distinción entre las reglas temporales realizadas en la línea de órdenes, y aquellas otras permanentes cargadas o guardadas en un archivo.
El archivo predeterminado es /etc/nftables.conf, que ya contiene una tabla simple de cortafuegos para ipv4/ipv6 llamada “inet filter”.
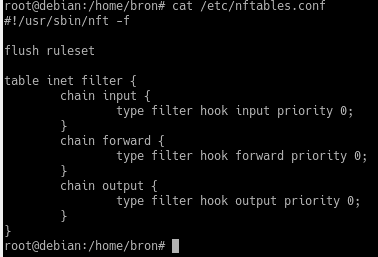
La utilidad de nftables en el espacio de usuario, nft, realiza la mayor parte de la evaluación del conjunto de reglas antes de pasarlas al Kernel del sistema operativo. Por tanto, si queremos ejecutar algún comando con nftables, tendremos que poner «nft» para poder ejecutarlo, la sintaxis es muy fácil de entender, mucho más fácil que iptables que ya hemos visto anteriormente.
En el caso de nftables, las reglas se almacenan en cadenas, que a su vez se almacenan en tablas. Para que los cambios permanezcan, debemos guardar las reglas directamente en el archivo /etc/nftables.conf. El comando que podemos utilizar para guardar estas reglas permanentemente y que se ejecuten con el reinicio del sistema, es el siguiente:
nft list ruleset > /etc/nftables.conf
A continuación, si hemos incorporado nuevas reglas manualmente, debemos reiniciar nftables para aplicar los cambios:
systemctl restart nftables.service
Todos los comandos deben ser ejecutados como administrador, ya sea con «sudo» o directamente con el usuario «root».
Funcionamiento y comandos básicos de nftables
Ahora bien, hay que conocer cuál es el funcionamiento y los comandos básicos puedes llegar a utilizar de nftables. Por tanto, si queremos consultar las reglas que tenemos dadas de alta en el firewall, tendremos que poner la siguiente orden:
nft list ruleset
Las tablas en nftables alojan las cadenas, en nftables no tenemos tablas integradas como en iptables. La cantidad de tablas que tengamos y los nombres que les demos depende del usuario. Cada tabla solo tiene una familia de direcciones, y solo se aplica a los paquetes de dicha familia. Las familias pueden ser:
| Familia en nftables | Equivalente en iptables |
| ip | iptables |
| ip6 | Ip6tables |
| inet | Iptables y ip6tables a la vez |
| arp | Arptables |
| bridge | ebtables |
Hay que tener en cuenta una diferencia clara y es que, con el uso de nftables, lo cierto es que las tablas y las cadenas se pueden configurar por completo. Por esto mismo, uno de los primeros pasos que hay que seguir es crear una tabla, como veremos más adelante para que, a continuación, se puedan pasar a desarrollar las diferentes cadenas en dichas tablas para podamos clasificar las reglas.
Ten en cuenta que la familia predeterminada es “ip”, es la que se usará si no se especifica ninguna familia a la hora de crear la tabla. Si queremos crear una regla que se aplique tanto a redes IPv4 como IPv6, lo ideal es usar “inet” ya que es la unificación de las dos familias. ¿Dónde usar esto de inet? Si queremos filtrar por ejemplo puertos TCP/UDP es una muy buena alternativa, para evitar «duplicar» reglas en redes IPv4 y IPv6.
Un detalle importante es que inet no funciona para las cadenas “nat”, solamente para las cadenas “filter”, es decir, cuando vamos a filtrar paquetes, pero no a hacer NAT. Debemos recordar que iptables también permitía realizar Source NAT y Destination NAT, con nftables ocurre exactamente lo mismo.
Crear una tabla
En el momento de tener claro cuál es el funcionamiento, hay que pasar a crear una tabla desde cero en la que se tendrás que fijar las reglas del firewall clasificadas en cadenas. Por tanto, la sintaxis que se utiliza para crear una tabla es la siguiente:
nft add table [familia] [nombre_tabla]
Ejemplos:
nft add table ip filtradonft add table inet filtrado
Tal y como podéis ver, podremos crear diferentes tablas con diferentes familias, además, podríamos crear una tabla con el mismo nombre de la tabla, siempre y cuando pertenezcan a familias diferentes, no hay ningún problema porque internamente nftables detectará que son tablas diferentes en función de la familia seleccionada.
Listar todas las tablas, cadenas y reglas
La sintaxis que se utiliza para listar todas las tablas es la siguiente:
nft list tables
La sintaxis que se utiliza para listar las cadenas y las reglas de una tabla en concreto:
nft list table [familia] [nombre_tabla]
Ejemplos:
nft list table ip filtradonft list table inet filtrado
Tal y como se puede ver, si tenemos dos tablas con el mismo nombre (pero que pertenecen a familias diferentes) podremos diferenciarlas poniendo la familia a la que pertenecen (ip, inet etc).
Borrar una tabla
Si queremos borrar una tabla, antes debemos asegurarnos de que no tiene ninguna cadena, si tiene alguna cadena no dará error indicando que la tabla no está vacía.
La sintaxis para eliminar una determinada tabla es:
nft delete table [familia] [nombre_tabla]
Debemos ser muy cuidadosos a la hora de borrar una tabla, porque no nos podemos equivocar de familia ni del nombre de la tabla. Además, un detalle muy importante es que primero debemos vaciar la tabla entera para posteriormente borrarla, no se permite borrar directamente una tabla si dentro hay contenido.
Vaciar una tabla
Si queremos vaciar la tabla entera, podemos hacerlo fácilmente:
nft flush table [familia] [nombre_tabla]
Este comando se encargará de vaciar la tabla entera por completo, debemos asegurarnos de poner bien la familia de la tabla para no tener problemas con ello.
Cadenas: qué son y cómo usarlas
Las cadenas se encargan de alojar las reglas que posteriormente debemos definir. A diferencia de las cadenas en iptables, no hay cadenas integradas en nftables. Esto significa que, si ninguna cadena utiliza ningún tipo o hook en el marco de netfilter, los paquetes de red que fluyan a través de esas cadenas no serán tocados por nftables, a diferencia de iptables. Las cadenas son de dos tipos:
- Cadena normal: puede usarse como un objetivo de salto («jump») para una mejor organización.
- Cadena base: punto de entrada para los paquetes de la pila de red, donde se especifica un valor de enlace. La familia es opcional, si no se especifica por defecto es “ip”.
Si queremos añadir una cadena normal, la sintaxis que debemos seguir es la siguiente:
nft add chain [familia] [ tabla] [cadena]
Si queremos añadir una cadena normal llamada “cadenaejemplo”, a la tabla “filtrado” creada anteriormente, y usamos la familia “inet” en tabla y cadena (no se pueden mezclar, da error), debemos escribir lo siguiente:
nft add table inet filtrado
nft add chain inet filtrado cadenaejemplo
Si queremos agregar una cadena base, la sintaxis que debemos utilizar es la siguiente:
nft add chain [familia] [ tabla] [cadena] { type tipo hook el_hook_que_sea priority prioridad policy política; }
- El “type” puede ser: filter, route o nat.
- El “hook” puede ser:
| Familia | Hooks |
| ip/ip6/inet | prerouting, input, forward, output, postrouting |
| arp | input, output |
| bridge | prerouting, input, forward, output, postrouting |
- Priority: es un valor entero. Las cadenas con números más bajos se procesan primero, pueden ser negativos, ideal para facilitar la gestión de las cadenas.
- Policy: puede ser accept, drop, queue, continue o return.
nft add chain [familia] [ tabla] [cadena] { type tipo hook el_hook_que_sea priority prioridad ; }
nft add table inet filtrado
nft add chain inet filtrado cadenabase { type filter hook input priority 0; policy accept; }
Tal y como podéis ver, aunque en principio pueda parecer todo muy confuso en comparación con iptables, esta sintaxis es mucho más intuitiva que iptables, además, podremos modificar las cadenas base sin ningún problema.
Modificar una cadena
Lo que tenemos que hacer es llamarla por su nombre, y definir la nueva regla de “policy” que queremos cambiar: accept o drop por ejemplo. Con el ejemplo anterior, si queremos cambiar la “policy” de accept a drop:el hook de input a output:
nft chain inet filtrado cadenabase { type filter hook output priority 0; policy drop}
Un detalle importante, es que no podremos cambiar todo de una cadenabase, no podremos modificarle el nombre, lo que sí podremos hacer es modificar la política o la prioridad, pero no el nombre, para hacer esto necesitarás crear una nueva cadena base que esté dentro de una tabla de una determinada familia elegida.
Borrar una cadena
Para borrar una cadena, lo primero que debemos hacer es eliminar todas las reglas de su interior. No debe haber ninguna regla, ni ningún objetivo “jump”. Para eliminar todas las reglas de una cadena:
nft flush chain [familia] [tabla] [cadena]
Para eliminar la cadena que ya está vacía:
nft delete chain [familia] [tabla] [cadena]
Tal y como podéis ver, borrar una cadena es realmente sencillo, pero tenéis que tener en cuenta en qué tabla está, y la tabla a qué familia pertenece, de lo contrario os devolverá un error indicando que no se encuentra esta cadena.
Reglas: qué son y cómo crearlas
Las reglas se construyen a través de expresiones, o bien a partir de declaraciones, y están contenidas dentro de las cadenas. La utilidad iptables-translate se encarga de “traducir” las reglas iptables al formato nftables: “iptables-translate –A INPUT –j ACCEPT”.
Para añadir una regla a una cadena:
nft add rule [familia] [tabla] [cadena] handle [identificador] [declaracion]
El “handle” es opcional, e indica la posición de la regla dentro de la cadena. Si no se especifica el handle, la regla se pone al final de la cadena. Para añadir una regla a una cadena (por arriba).
nft insert rule [familia] [tabla] [cadena] handle [identificador] [declaracion]
Para eliminar una regla individual en concreto, debemos eliminarlas gracias al handle utilizado, o en la posición donde nftables la ha colocado. Para ver los identificadores de las reglas debemos listarlo:
nft –-handle list
Para eliminarla:
nft delete rule [tabla] [cadena] handle [identificador]
nft delete rule tabla input handle 10
Las reglas en nftables incluyen una expresión de coincidencia, y luego, una declaración que resuelva (si coinciden).
Las coincidencias que tenemos disponibles en nftables son:
- meta (iif, iifname, oif, oifname): índice, nombre, de la interfaz de entrada/salida
- icmp: type [tipo de icmp]
- icmpv6: type [tipo de icmpv6]
- Ip: daddr (dirección de destino), saddr (dirección de origen)
- Ipv6: daddr (dirección de destino), saddr (dirección de origen)
- Tcp, udp y sctp: dport y sport
- Ct: state [new | established | related | invalid]
- Las declaraciones resolutivas son: accept, drop, queue, continue, return, [cadena] jump y [cadena] goto.
A continuación, podéis ver un ejemplo donde bloqueamos una dirección IP de origen, y también bloqueamos tráfico TCP y UDP en un determinado puerto:
nft add table inet firewall
nft add chain inet firewall bloqueo { type filter hook input priority 0; policy accept ; }
nft add rule inet firewall bloqueo ip saddr 192.168.1.2 counter drop
nft add rule inet firewall bloqueo ip saddr 192.168.1.3 tcp dport 80 drop
nft add rule inet firewall bloqueo ip saddr 192.168.1.3 udp dport 80 drop
Ahora vamos a crear un “ipset” con nftables, aunque lógicamente no se hace igual. Debemos recordar que IPset nos permitía crear un listado enorme de direcciones IP y direcciones de red para aceptar o denegar. Esta función de nftables nos permitirá realizar algo similar, el objetivo es poder añadir o quitar elementos fácilmente, sin tener que definir nuevas reglas constantemente.
nft add set inet firewall ips_baneadas { type ipv4_addr;}
nft add element inet firewall ips_baneadas { 192.168.1.2 }
nft add element inet firewall ips_baneadas { 192.168.1.3, 192.168.4.66 }
nft add rule inet firewall bloqueo ip saddr @ips_baneadas counter drop
Los “type” pueden ser: “ipv4_addr, ipv6_addr, ether_addr, inet_proto, inet_service”
Es muy recomendable revisar las reglas con cierta frecuencia, para comprobar que se siguen cumpliendo los requisitos para permitir o denegar el tráfico que nosotros deseemos. Si estamos en un entorno estático donde no haya habido cambios, entonces no será necesario realizar un mantenimiento de estas reglas de forma regular, sin embargo, en las redes que sí cambian, tendremos que encargarnos de ello.
Source NAT: configuración del postrouting en nftables
La configuración del Source NAT en nftables es muy similar a como lo hacíamos con iptables. Lo primero que debemos hacer es crear una tabla con el nombre que queramos, y crear una cadena, a continuación, definiremos el hook y la prioridad
nft add table nat
nft add chain nat prerouting { type nat hook prerouting priority 0 ; }
nft add chain nat postrouting { type nat hook postrouting priority 100 ; }
Una vez que hemos creado la cadena, ahora definiremos la regla. Esta regla la podemos utilizar cuando la dirección IP pública, o la IP que queremos NATear sea la misma siempre:
nft add rule nat postrouting ip saddr 192.168.1.0/24 oif eth0 snat 1.2.3.4
O también masquerade para que no dependamos de que la dirección IP sea la misma:
nft add rule nat postrouting masquerade
Destination NAT: configuración del prerouting en nftables
La configuración del Destination NAT en nftables es muy similar a como lo hacíamos con iptables. Lo primero que debemos hacer es crear una tabla con el nombre que queramos, y crear una cadena, a continuación, definiremos el hook y la prioridad
nft add table nat
nft add chain nat prerouting { type nat hook prerouting priority 0 ; }
nft add chain nat postrouting { type nat hook postrouting priority 100 ; }
Una vez que hemos creado la cadena, ahora definiremos la regla. Esta regla sirve para hacer el reenvío de puertos TCP con destino 80 y 443, a la dirección IP privada definida:
nft add rule nat prerouting iif eth0 tcp dport { 80, 443 } dnat 192.168.1.120
En el caso de querer hacer redirección de puertos, para utilizar un Proxy o realizar un MitM, lo haremos de forma muy parecida en iptables:
nft add table nat
nft add chain nat prerouting { type nat hook prerouting priority 0 ; }
nft add chain nat postrouting { type nat hook postrouting priority 100 ; }
Una vez que hemos creado la cadena, ahora definiremos las reglas.
nft add rule nat prerouting redirect
nft add rule nat prerouting tcp dport 22 redirect to 2222
Otros ejemplos de nftables
Usamos “ct” para controlar las conexiones nuevas, establecidas y relacionadas.
ct state established,related accept
Conexiones no válidas:
ct state invalid drop
Controlar los diferentes tipos de ICMP
ip protocol icmp icmp type { destination-unreachable, router-solicitation, router-advertisement, time-exceeded, parameter-problem } accept
Controlar un límite de pings recibidos
ip protocol icmp icmp type echo-request limit rate over 10/second burst 4 packets drop
Limitar un número de intentos máximos de SSH
tcp dport ssh ct state new limit rate 15/minute accept
Si queremos “jump” o saltar a otra cadena, podemos hacerlo muy fácilmente y de manera más intuitiva:
table inet filter {
chain ssh_server {
tcp dport ssh accept
}
chain input {
type filter hook input priority 0;
ip saddr 10.10.2.2/24 jump ssh_server
drop
}
}
Tal y como habéis visto, nftables es bastante más fácil de utilizar que iptables, es más intuitivo. No obstante, para los que estamos acostumbrados a iptables, tendremos que trabajar y actualizarnos con la nueva sintaxis que incorpora nftables. Esperamos que este tutorial sobre las características y configuración básica de nftables os sirva de ayuda y practiquéis con el nuevo firewall Linux.
OpenSnitch, un firewall para aplicaciones Linux
Los sistemas operativos basados en Linux tienen una gran cantidad de protecciones para mitigar los ataques, evitar la escalación de privilegios y otros ataques muy comunes a este sistema operativo. Aunque Linux es muy seguro si se configura bien, no por ello debemos dejar de cuidar nuestro sistema operativo por completo, puesto que las amenazas siguen existiendo. En la actualidad hay disponibles varios cortafuegos para Linux, los cuales podemos instalar y utilizar para hacer nuestro sistema Linux más seguro y fiable.
OpenSnitch es una aplicación de firewall escrita en Python para sistemas operativos basados en GNU/Linux, por lo que, en principio, cualquier sistema operativo basado en GNU/Linux es compatible con este programa que nos añadirá un extra de seguridad.
El método de funcionamiento de OpenSnitch consiste en comprobar todas las solicitudes de conexión a Internet realizadas por todas las aplicaciones que se han instalado en el sistema operativo. Este programa permite la creación de reglas específicas para las diferentes aplicaciones que tengamos instaladas en nuestro ordenador o servidor Linux, estas reglas permitirán o denegarán el acceso a Internet cuando estas lo soliciten. Es posible que, una aplicación que no tiene creada una regla, intente acceder a Internet, en ese momento, aparecerá un cuadro de texto que nos dará la opción de permitir la conexión o denegarla, sin tener que meternos de manera tan específica a crear una regla para la aplicación en concreto.
Otras opciones disponibles son la posibilidad de grabar la decisión como una regla para que se quede en el listado para las próximas veces que esa aplicación en concreto requiera de acceso a Internet, podremos aplicar la regla a la URL exacta del dominio al que se intenta llegar. También tendremos la posibilidad de permitirlo temporalmente, y que cuando reiniciemos el servidor o el ordenador esta regla añadida desaparezca.
Todas las reglas que creamos en OpenSnitch se almacenarán como archivos JSON (tipología de archivo que solo puede manejar OpenSnitch), de esta manera, podremos modificarlas más tarde si fuese necesario de manera manual. OpenSnitch tiene una interfaz gráfica de usuario muy intuitiva, que nos permitirá ver qué aplicaciones están accediendo a internet en ese momento, qué dirección IP está siendo usada por el equipo, qué usuario está usando tanto el sistema como el propio OpenSnitch y qué puerto se está usando para todo ello.
Otra opción muy útil que posee OpenSnitch es la de crear un reporte en formato CSV con toda la información, aquí encontraremos la configuración del firewall y todas las aplicaciones guardadas.
Instalación de OpenSnitch en Linux
Vamos a proceder con la instalación de OpenSnitch, como podrás ver todos los comandos que usaremos para la instalación están destinadas a usuarios de Debian o Ubuntu así que, si estás utilizando otra distribución, tendrás que ajustar los comandos a la distribución que tengas instalada en tu equipo.
Primero, instalaremos todo lo necesario para que OpenSnitch pueda funcionar, incluyendo Go y también Git, ambos son totalmente necesarios para la correcta instalación, ya que no tenemos Opensnitch en los repositorios oficiales de las diferentes distribuciones Linux. Como no podía ser de otra manera, tendremos que iniciar sesión como root en nuestro sistema operativo, o ejecutar el comando «sudo» delante de la orden de instalación a través de los repositorios. Nuestra recomendación, como vamos a tener que realizar varios pasos e instalar varios programas, es que iniciéis sesión con el popular «sudo su» para ya tener permisos de superusuario y no necesitar ejecutar el «sudo» delante de cada comando.
sudo apt-get install protobuf-compiler libpcap-dev libnetfilter-queue-dev python3-pip golang git
go get github.com/golang/protobuf/protoc-gen-go
go get -u github.com/golang/dep/cmd/dep
python3 -m pip install --user grpcio-tools
A continuación, nos dispondremos a clonar el repositorio de OpenSnitch. Al inicio es probable que la instalación arroje un mensaje indicando que no se encontraron archivos Go. Este mensaje lo ignoraremos, pero si nos asalta otro comunicándonos que nos falta el git, deberemos para para instalarlo. Por defecto el «GOPATH» está en /home/usuario/go
go get github.com/evilsocket/opensnitch
cd $GOPATH/src/github.com/evilsocket/opensnitch
Si la variable de entorno $GOPATH no está configurada correctamente, obtendremos un error que nos dirá «no se encontró esta carpeta» en el comando anterior. Para solucionar esto usaremos el comando cd para dirigirnos a la ubicación de la carpeta «/home/usuario/go/src/github.com/evilsocket/opensnitch» que estaba en de serie en la instalación del sistema. Ahora, lo instalamos de la forma típica:
make
sudo make install
Una vez instalado correctamente, lo habilitaremos de la siguiente forma:
sudo systemctl enable opensnitchd
sudo service opensnitchd start
opensnitch-ui
Y accederemos a la interfaz gráfica de usuario donde tendremos toda la información y acciones que podremos realizar con este gran programa.
Experiencia de uso con OpenSnitch
Este programa es realmente útil para permitir o denegar el tráfico de red de las diferentes aplicaciones, navegadores web, clientes FTP, programas como Skype, Google Drive y cualquier programa que necesite de conexión a Internet para funcionar. Con OpenSnitch podremos controlar en detalle todas las conexiones, y permitir o denegar todo a nivel de aplicación, y no a nivel de dirección IP o puerto como ocurre con el popular firewall iptables o nftables que incorporan los sistemas operativos basados en Debian de forma predeterminada.
Es posible que al principio tengamos decenas de mensajes indicándonos que una aplicación ha intentado acceder a Internet, esto es completamente normal al principio, porque todas las aplicaciones deben ser permitidas específicamente en el programa, por tanto, tendremos la mejor seguridad posible porque está configurado en modo restrictivo. Por defecto se bloquea todo, excepto lo que está específicamente permitido en el firewall de aplicación.
Por último, nos gustaría indicar que todas las reglas creadas en un determinado momento, se pueden exportar fácilmente en formato JSON, para importarlo en otro sistema operativo Linux, es decir, podremos realizar pruebas en local o en una máquina virtual, y posteriormente copiar este archivo JSON en el servidor en producción, sin tener ningún tipo de problema.
Gracias al buen funcionamiento de OpenSnitch, podremos controlar todos los accesos de cualquier programa que tengamos en nuestro equipo, si quieres un completo firewall a nivel de aplicación, este software es ideal para ti.
Cuál elegir
Después de haber explicado las principales diferencias entre un firewall de software y de hardware, vamos a hablar de cuándo utilizar una u otra opción. De esta forma podrás elegir cuál te conviene más según el uso que le vayas a dar y de qué manera quieras proteger tus dispositivos. Y es que, en función de las necesidades de cada usuario, una u otra opción será la más acertada. Por lo que es importante tener en cuenta los siguientes aspectos:
Proteger un dispositivo o muchos
Lo primero que debes pensar es en qué vas a proteger. No es lo mismo un único dispositivo, como podría ser un ordenador o móvil, que toda una red, a la que vas a poder conectar muchos dispositivos de todo tipo. Esto será clave para elegir qué te conviene más y adquirir un dispositivo físico o un programa
Si únicamente vas a proteger un equipo, como puede ser un ordenador, te conviene más utilizar un firewall de software. En cambio, si quieres proteger toda una red lo ideal es que utilices un firewall de hardware. De esta forma protegerás todo lo que conectes a tu red. Por lo que es conveniente tener en cuenta este punto para elegir adecuadamente el firewall que se quiere tener, ya sea de software o de hardware.

Usuario doméstico o empresa
Pero si hay un motivo claro para elegir una opción u otra es ver si lo vas a usar a nivel doméstico o para una empresa. Lo normal es que, para usarlo de forma personal, para proteger un ordenador o móvil, lo mejor sea utilizar un firewall de programa. No vas a requerir más que eso y así no tienes que gastar nada o muy poco.
Si quieres proteger una empresa, donde va a haber muchos aparatos de todo tipo conectados, en ese caso sí puede ser interesante utilizar un cortafuegos físico. Es lo que va a permitir bloquear las conexiones maliciosas para toda la red y evitar así problemas que afecten a componentes esenciales de una organización.
Dónde lo vas a usar
El lugar donde lo vayas a necesitar también será un factor clave para elegir una u otra opción. Si vas a usar un ordenador en diferentes redes, como puede ser en tu casa, en el trabajo, en una biblioteca, de viaje… Sin duda lo ideal es tener un firewall a nivel de software, ya que lo vas a poder llevar a cualquier lado.
Por otra parte, si lo vas a usar únicamente en tu vivienda, trabajo o cualquier sitio fijo, entonces sí que podría interesarte un firewall de hardware. En ese caso no lo vas a poder mover, pero tampoco tendrías necesidad para ello, ya que estarías en tu propia vivienda o trabajo y puede estar en ese sitio de manera fija sin que sea un inconveniente.
En definitiva, como has podido ver tienes la opción de utilizar un firewall de software o de hardware. Son dos opciones diferentes, pero tienen el mismo objetivo: proteger tus conexiones y evitar la entrada de amenazas a tu red y a tus dispositivos. Según sea el caso, puede que te convenga más utilizar una u otra opción.
Cómo hacer una auditoría de seguridad en Linux
Linux es considerado un sistema operativo más seguro que Windows. Esto es así principalmente porque existen menos malware creados para atacar las múltiples distribuciones que hay. Sin embargo, eso no significa que no haya problemas que afecten a la privacidad, seguridad o provoquen errores con las aplicaciones instaladas.
Lynis es una auditoría muy completa que podemos utilizar en Linux. Está disponible para distribuciones tan populares como Ubuntu, Fedora, Debian y OpenSUSE. Lo que hace básicamente es analizar todo el software instalado en nuestro equipo y busca posibles problemas que debamos corregir. De esta forma sabremos si tenemos que realizar cambios, instalar actualizaciones, etc. Son muchas las herramientas que hay de este tipo. Sin embargo, Lynis es muy interesante precisamente por ser completa y también por estar disponible tanto para sistemas de escritorio como para servidores. Es de código abierto. Podemos acceder a su web para encontrar todo tipo de información, así como su descarga. Pero también podemos instalarla directamente desde nuestro sistema, a través del terminal. Por ejemplo, en nuestro caso lo hemos probado en Ubuntu.
Cómo usar Lynis en Linux
Para comenzar a utilizar Lynis podemos agregarlo desde la terminal a través del comando «sudo apt-get install lynis». Nos solicitará la contraseña de administrador y a continuación descargará los paquetes necesarios para su instalación en el sistema.
A partir de ese momento ya podremos comenzar a utilizar Lynis. Si queremos algo básico y rápido podemos ejecutar el comando lynis –Q. Lo que hace es un análisis rápido para detectar posibles problemas de seguridad que encuentre en el software instalado.
Comenzará a analizar los diferentes apartados de nuestro sistema y analizarlos uno a uno. Además, nos mostrará información de cada uno de ellos, para que tengamos los datos necesarios a la hora de tomar posibles medidas con el objetivo de mejorar nuestra seguridad.
En el primer apartado veremos información relacionada con el sistema operativo instalado, el nombre de usuario, la versión del kernel, la plataforma, etc. También comenzará a realizar diferentes test, comprobar la existencia de diferentes archivos, la seguridad de las funciones, procesos, archivos del sistema, etc. Es una herramienta de auditoría muy completa, como podremos ver.
También nos muestra apartados como impresoras que tengamos conectadas, firewall, servidores, redes… Todo ello para poder detectar posibles problemas que pueda haber y corregirlos para no tener complicaciones a nivel de seguridad. Muy útil si por ejemplo tenemos servidores web instalados.
En definitiva, Lynis es una interesante herramienta con la que podremos realizar auditorías en nuestro sistema Linux, tanto a nivel de escritorio como de servidor. En nuestro caso lo hemos probado en Ubuntu, pero está disponible para muchas de las principales distribuciones de Linux.
Proteger nuestros sistemas no es solo contar con un antivirus. Es importante mantener todos los aspectos básicos de seguridad siempre adecuadamente. Algo esencial es contar con las últimas versiones. Son muchas las ocasiones en las que pueden surgir problemas de vulnerabilidades en las aplicaciones y sistemas que utilizamos. Esos fallos pueden ser aprovechados por los piratas informáticos para llevar a cabo ataques.
Por tanto, más allá de tener herramientas de seguridad también debemos asegurarnos de contar con las últimas versiones y, por supuesto, que no existen vulnerabilidades en los programas y herramientas que utilicemos. Para ello también podemos hacer uso de servicios como Lynis que nos analice en sistema en busca de problemas.
También, como recomendación añadida, debemos tener presente siempre el sentido común. No cometer errores a la hora de navegar por la red, descargar programas y configurar los equipos. Esto es algo que debemos aplicar siempre sin importar el tipo de sistema operativo o dispositivo que estemos utilizando.
Cómo usar Debsecan
Esta herramienta no se encuentra instalada por defecto en el sistema operativo, por tanto, debemos instalarla manualmente a través de los repositorios oficiales de la distribución. Para instalarla, deberemos ejecutar la siguiente orden:
sudo apt install debsecan
En la siguiente captura podéis ver todos los paquetes adicionales que debe instalar para que funcione correctamente, el especio total de disco que usaremos será de menos de 60MB, por lo que no es un programa que necesite demasiados recursos a nivel de almacenamiento.
Una vez que lo hayamos instalado, podemos ejecutarlo con la ayuda, para que nos indique qué argumentos podremos utilizar y qué opciones tenemos disponibles:
debsecan --help
En la siguiente captura podéis ver todas las opciones que tenemos disponibles al utilizar esta herramienta:
También podremos ejecutar las páginas man para la ayuda más completa de esta herramienta, para abrir el manual completo, basta con ejecutar lo siguiente:
man debsecan
Si ejecutamos este comando, accederemos a la documentación completa de la herramienta, donde veremos una explicación detallada de todo lo que es capaz de hacer, cómo lo hace y también qué comandos debemos ejecutar para realizar todas las pruebas de seguridad en el sistema operativo.
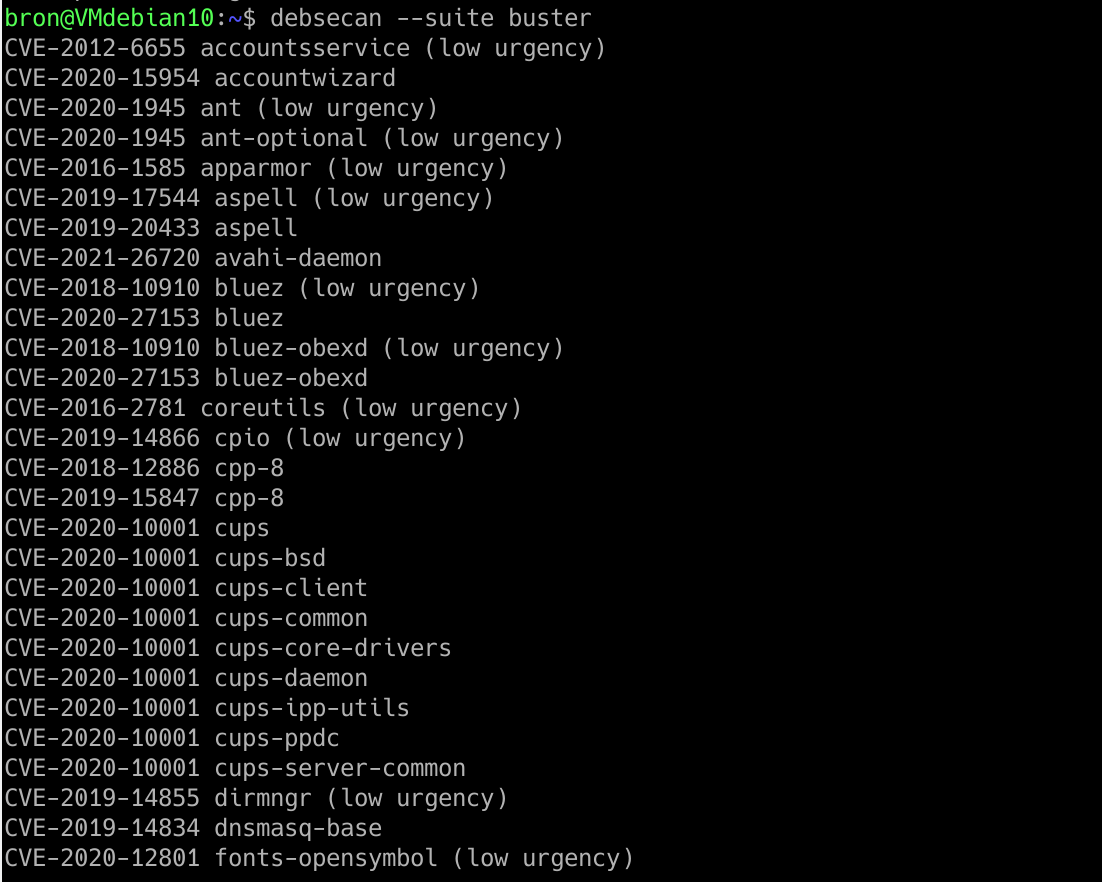
La forma de funcionamiento de debsecan es realmente fácil, simplemente deberemos ejecutar el programa con el argumento de la versión de Debian que estamos utilizando:
debsecan --suite buster
Una vez que ejecutemos este comando, nos saldrá un listado de todas las vulnerabilidades que ha tenido o tenemos en esta versión, y también una descripción de si hay poca urgencia por solucionarlo, si ya está solucionado, aunque tenga poca urgencia, o si simplemente está solucionado el problema. También nos mostrará si no está solucionado el fallo de seguridad, pero sí lo tiene en la base de datos de vulnerabilidades.
Tenemos la posibilidad de configurar debsecan para que siempre utilice la versión de «Debian Buster» (la que estamos usando), sin necesidad de definirlo en un argumento. Para hacer esto, deberemos ejecutar la siguiente orden:
sudo dpkg-reconfigure debsecan
Y nos saldrá la siguiente pantalla, donde deberemos elegir la versión de nuestra distribución, en la siguiente captura podéis ver los detalles:
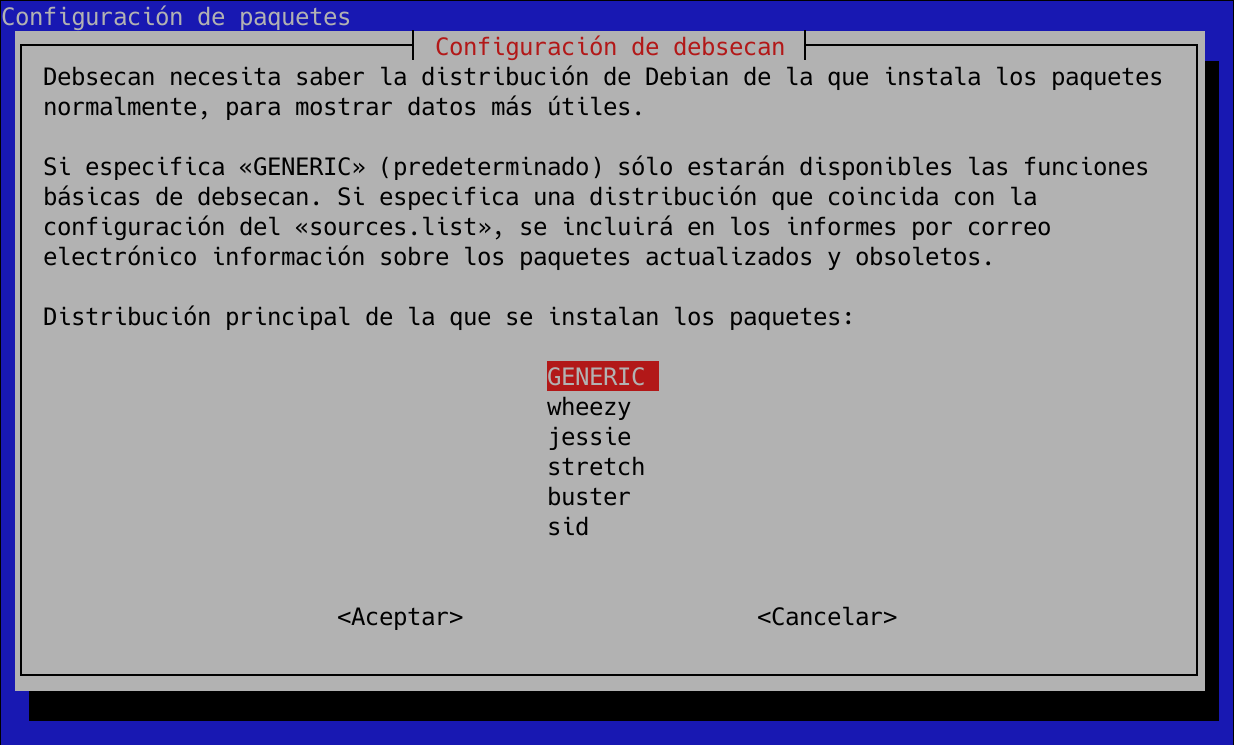
Si aprovechamos a utilizar este asistente de configuración, también podremos configurar debsecan para que nos envíe automáticamente y una vez al día, cualquier cambio que ocurra en las vulnerabilidades vía email:
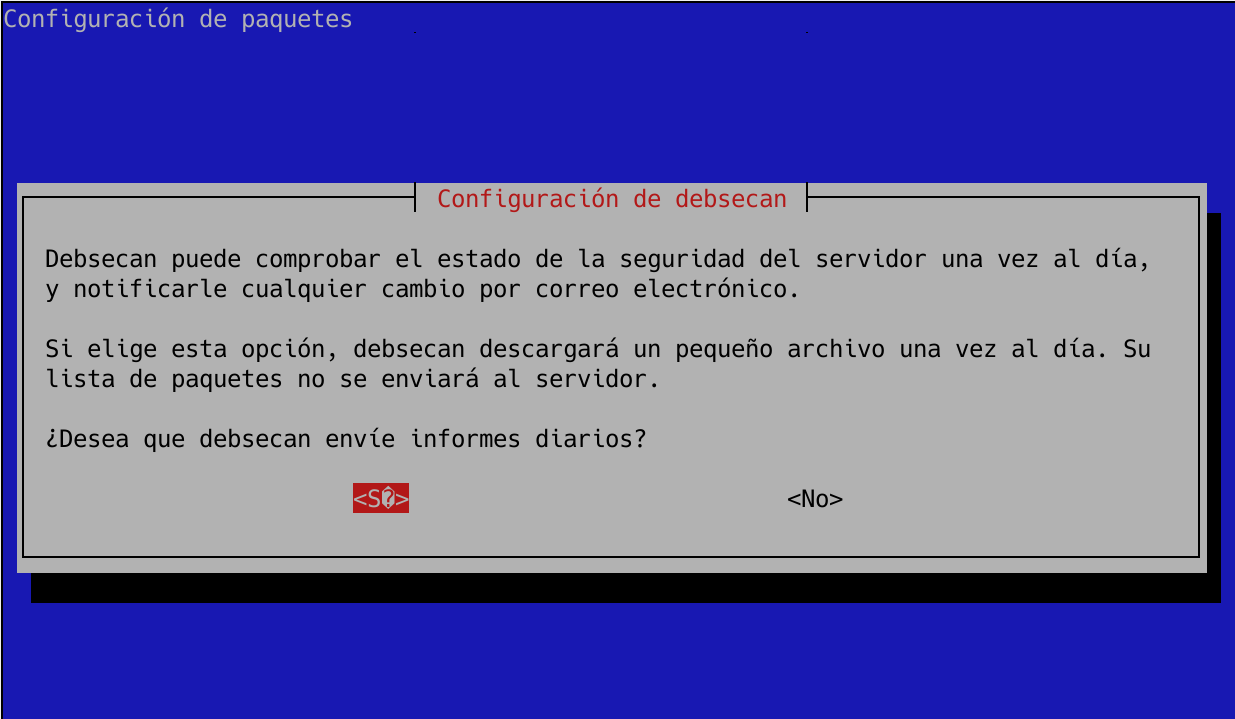
A continuación, definiremos nuestra dirección de correo electrónico, y el propio sistema operativo se encargará de mandarnos un email diario sobre el estado de la seguridad del sistema. También nos preguntará que Debsecan descarga la información de vulnerabilidades desde Internet, si el servidor no está conectado a Internet, o no queremos que haga solicitudes a Internet, podremos definir una URL con la información de vulnerabilidades para añadirla a su base de datos. Una vez configurado, ya podremos ejecutar debsecan sin necesidad de poner «–suite».
Una orden muy interesante es la siguiente:
debsecan --suite buster --only-fixed
Esta opción enumera las vulnerabilidades para las que hay una solución disponible, y tengamos que actualizar el sistema operativo para librarnos de ellas. Hay que tener en cuenta que es posible que aparezca una solución, aunque el paquete todavía no esté disponible en el repositorio de Debian para su actualización o instalación. Si nos aparece vacío, significa que tenemos todas las actualizaciones y parches disponibles:

Si ejecutamos la orden siguiente:
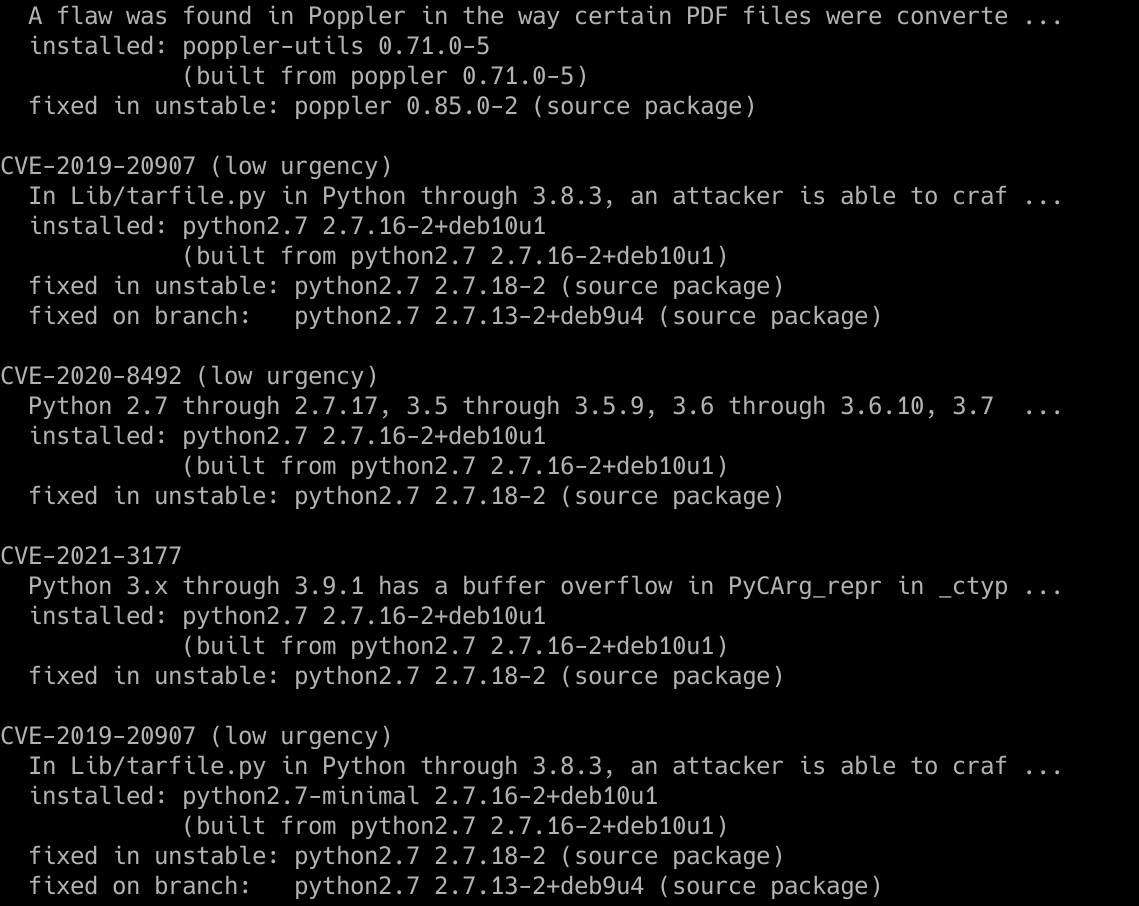
debsecan --format detail
Nos mostrará todas las vulnerabilidades arregladas o no pero más en detalle, además, nos mostrará qué versión del software tiene el problema de seguridad, y qué versión lo soluciona, tanto a nivel de parche inestable como del repositorio principal. Es posible que el parche esté en el repositorio «unstable» durante semanas o meses, por lo que debemos tenerlo muy en cuenta.
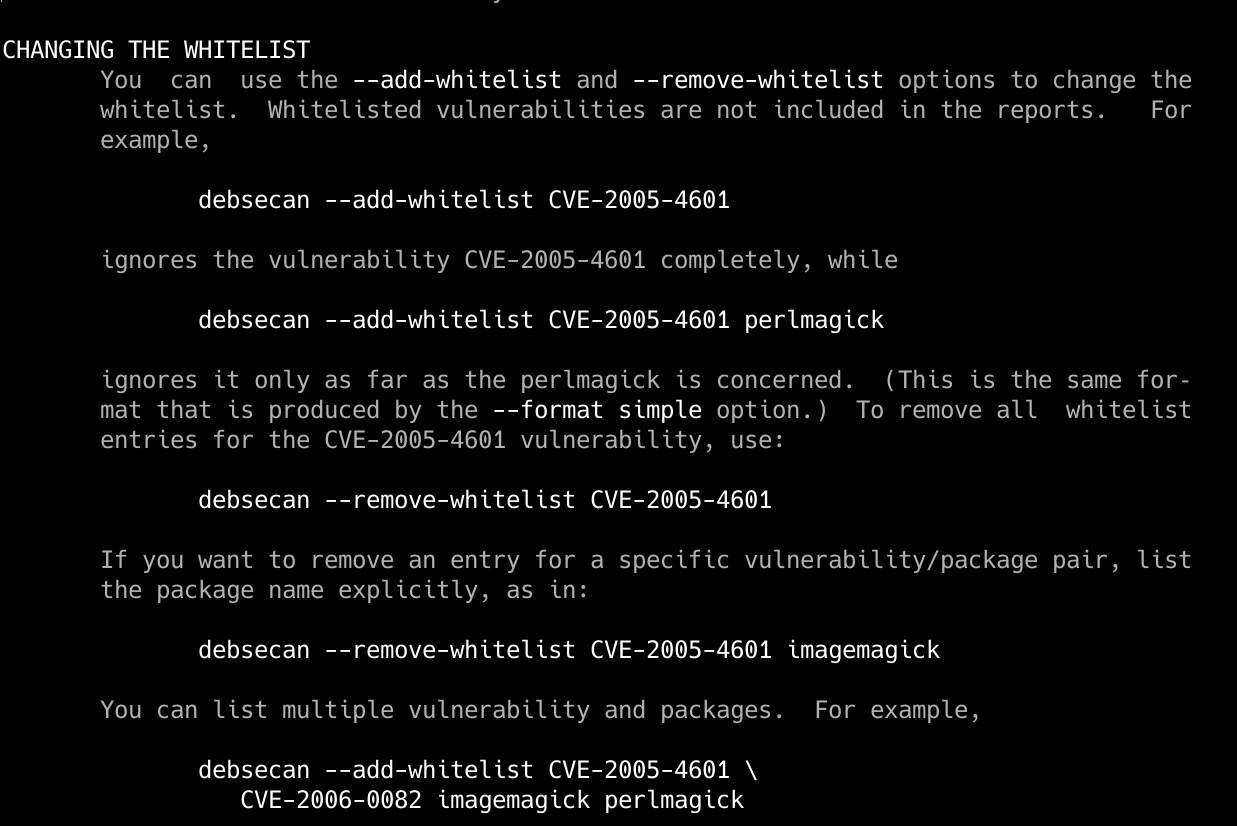
En las páginas man, podremos ver más en detalle cómo funciona la whitelist. Imaginemos que queremos poner un determinado paquete con código CVE en una lista blanca, de tal forma que nunca nos aparezca en el listado del reporte, para hacerlo, simplemente tendremos que ejecutar lo siguiente:
debsecan --add-whitelist CVE-XXXX-XXXX
Tendremos que poner el código CVE para que se añada a la lista blanca. En caso de quitar algo de la lista blanca también podremos hacerlo fácilmente, para que vuelva a incluirse en los reportes diarios de vulnerabilidades.
La herramienta debsecan es muy útil para mantenernos informados de todos los fallos de seguridad que se van encontrando y que afectan a nuestro sistema operativo Debian, ya sea al propio sistema operativo, o a los paquetes que tengamos instalados. Gracias a debsecan podremos recibir emails diarios con las novedades en cuanto a la resolución de las vulnerabilidades por parte del equipo de desarrollo de los diferentes softwares.
Como medida de seguridad fundamental en cualquier servidor, nunca debemos instalar programas o paquetes que no utilicemos, para reducir al mínimo la superficie de exposición a una vulnerabilidad grave, por supuesto, realizar un hardening del servidor es algo fundamental.
Por último, debemos prestar especial atención a las actualizaciones que tengamos en el sistema operativo, porque es recomendable revisar diariamente estas actualizaciones e incluso realizar scripts automáticos para actualizar los repositorios cada cierto tiempo y que nos avise por correo electrónico sobre los cambios que haya, de esta forma, podremos conocer diariamente e incluso cada hora si se ha lanzado una nueva actualización para nuestro sistema operativo. También se podría automatizar la actualización automática del sistema operativo Debian, pero no es recomendable, sobre todo si lo tenemos en un entorno de producción, porque algo podría salir mal e incluso podríamos estar utilizando software que tengamos instalado y requiera una nueva actualización de software.